Regulatory task key. Scheduled and background tasks (creation, configuration, launch)
When working in 1C, there are many routine operations that must be launched or formed according to a schedule to perform one or another action, for example: posting documents or loading data into 1C from a website.
I recently posted an article: It's time to automate this:
Routine and background tasks
The job engine is designed to perform any application or functionality on a schedule or asynchronously.
The task mechanism solves the following problems:
- Ability to define regulatory procedures at the system configuration stage;
- Execution of specified actions according to schedule;
- Making a call to a given procedure or function asynchronously, i.e. without waiting for its completion;
- Tracking the progress of a specific task and obtaining its completion status (a value indicating whether it was successful or not);
- Obtaining a list of current tasks;
- Ability to wait for one or more tasks to complete;
- Job management (possibility of cancellation, blocking of execution, etc.).
The job mechanism consists of the following components:
- Metadata of routine tasks;
- Regular tasks;
- Background jobs;
- Task Scheduler.
Background jobs & are designed to perform application tasks asynchronously. Background tasks are implemented using the built-in language.
Scheduled tasks & are designed to perform application tasks on a schedule. Routine tasks are stored in the information base and are created based on metadata defined in the configuration. Metadata of a regulatory task contains information such as name, method, use, etc.
A routine task has a schedule that determines at what times the method associated with the routine task must be executed. The schedule, as a rule, is specified in the information base, but can also be specified at the configuration stage (for example, for predefined routine tasks).
The task scheduler is used to schedule the execution of routine tasks. For each scheduled job, the scheduler periodically checks whether the current date and time matches the schedule of the scheduled job. If it matches, the scheduler assigns that task to execution. To do this, for this scheduled task, the scheduler creates a background task, which performs the actual processing.
I think that’s enough with the description - let’s get down to implementation:
Creating a routine task
Method name– path to the procedure that will be executed in a background job according to a given schedule. The procedure must be in a common module. It is recommended not to use standard common modules, but to create your own. Don't forget that background jobs run on the server!
Usage– sign of using a routine task.
Predetermined– indicates whether the routine task is predetermined.
If you want the routine task to work immediately after being placed in the database, specify the attribute Predetermined. Otherwise, you will need to use the “Job Console” processing or trigger the task to run programmatically.
Number of retries when a job terminates abnormally– how many times the background job was restarted if it was executed with an error.
Retry interval when job terminates abnormally– how often the background job will be restarted if it was completed with an error.
Setting up a schedule
Schedule completing the task:
| Every hour, just one day | RepeatDays Period = 0, RepeatDays Period = 3600 |
| Every day once a day | RepeatDays Period = 1, RepeatDays Period = 0 |
| One day, one time | PeriodRepeatDays = 0 |
| Every other day once a day | PeriodRepeatDays = 2 |
| Every hour from 01.00 to 07.00 every day | PeriodRepeatDays = 1RepeatPeriodDuringDay = 3600StartTime = 01.00 End Time = 07.00 |
| Every Saturday and Sunday at 09.00 | RepeatDays Period = 1WeekDays = 6, 7StartTime = 09.00 |
| Every day for one week, skip a week | PeriodRepeatDays = 1PeriodWeeks = 2 |
| At 01.00 once | Start Time = 01.00 |
| Last day of every month at 9:00. | PeriodRepeatDays = 1DayInMonth = -1StartTime = 09.00 |
| Fifth day of every month at 9:00 | PeriodRepeatDays = 1DayInMonth = 5StartTime = 09.00 |
| Second Wednesday of every month at 9:00 | PeriodRepeatDays = 1DayWeekMonth = 2DaysWeek = 3 Start Time = 09.00 |
Features of executing background jobs in file and client-server variants
The mechanisms for executing background jobs in the file and client-server versions are different.
In file version you need to create a dedicated client process that will perform background jobs. To do this, the client process must periodically call the global context function ExecuteJobProcessing. Only one client process per infobase should process background jobs (and, accordingly, call this function). If a client process has not been created to process background jobs, then when programmatically accessing the job engine, the error “Job Manager is not active” will be displayed. It is not recommended to use a client process that processes background jobs for other functions.
Once the client process processing background jobs is started, other client processes are able to programmatically access the background job engine, i.e. can run and manage background jobs.
In client-server version To execute background jobs, a task scheduler is used, which is physically located in the cluster manager. For all queued background jobs, the scheduler gets the least loaded worker process and uses it to run the corresponding background job. The worker process executes the job and notifies the scheduler of the execution results.
In the client-server version, it is possible to block the execution of routine tasks. The execution of routine tasks is blocked in the following cases:
- An explicit blocking of routine tasks has been installed on the information base. The lock can be set via the cluster console;
- There is a connection block on the infobase. The lock can be set via the cluster console;
- The SetExclusiveMode() method with the True parameter was called from the built-in language;
- In some other cases (for example, when updating the database configuration).
Processing the launch and viewing of scheduled tasks you can download here.
Platforms: 1C:Enterprise 8.3, 1C:Enterprise 8.2, 1C:Enterprise 8.1
Configurations: All configurations
2012-11-13
53853
In document management, there are tasks that require periodic execution - for example, on the twentieth, or daily. As a rule, companies create certain rules specifically for this purpose, which indicate when and how the necessary task should be performed, and who should control the process. Such tasks are performed according to regulations and are called regulated.
Quite often, monitoring regulations are observed in IT. This method is very familiar to administrators, since for this purpose there are special programs used to periodically check the functionality of the network infrastructure and servers. They notify the administrator about detected problems via SMS or email.

A similar system operates for webmasters, and the site’s availability is checked within 24 hours. Using the “Routine tasks” mechanism in 1C, monitoring tasks are carried out, as well as periodic tasks that are performed according to a schedule in automatic mode in 1C. Let's take a closer look at this topic.
Scheduled tasks 1C
The 1C object, called “Routine tasks,” makes it possible to process information not after a problem occurs, but according to a schedule. In the configurator, a routine task is a way to set settings and set a schedule. In addition, it is possible to subsequently change the schedule in 1C Enterprise mode.
When using a file database, jobs are not automatically executed. In order to start the process, you need to start a 1C session in 1C Enterprise mode and start executing a routine task in it.
All standard configurations have a user setting that allows you to specify that when 1C is running, routine tasks will be performed automatically.
Using the client-server version of 1C makes it possible to automatically perform tasks on the server. At the scheduled time, a background job is launched, which performs the necessary actions. For parallel computing on the server, a background job can be created from the program text using the 1C language, without using a scheduled 1C job. The action of a scheduled task can be temporarily disabled using the 1C server management console.
Adding a scheduled task
Routine tasks are located in - Configurator - General - Routine tasks. Add a new "task" and provide a name. Next, you need to go to the “Tasks” properties. And select Method Name. Here, you need to specify a handler function, just as it happens in an event subscription. This function will be located in the general module and marked with a “bird” Server in the properties. This means that the required module must be added in advance.

The name of the task in the Properties of a scheduled task allows you to define its name, which will then appear in the task management tools. The Routine Task Properties function is a key that allows you to group several different routine tasks. In this case, only one task with the same key value can be launched at a time. Here, the value can be arbitrary, but it must be filled in, since an empty value is not taken into account by the system.
In Accounting edition 2.0, which is a standard configuration, routine tasks such as: “Recalculation of totals” and “Updating the configuration” are predefined, but such as, for example, “Deferred movements” and “Data exchange” are not predefined.
Retry on abnormal termination - restarts the current job. Designed to perform a launch that was not successful the first time. Here, it is indicated how many times you can restart and after what time has passed after an abnormal termination.
Monitoring and management tools for routine tasks 1C
The standard processing “Task Console”, which can be found on the ITS disks, is responsible for managing a routine task. This processing is a universal external standard processing 1C. As a rule, it is not included in the configuration, but is purchased separately.

With its help you can perform the following actions:
Turn on and off a scheduled task;
Assign and change schedules;
Designate the user name with which the routine task will be performed;
See completed tasks (when and with what result), as well as task errors;
Routine task and copies of databases
When using server 1C, the following moment may arise:
To program, you need to make a copy of the working database;
The need to work in copies of the database (testing);
For some reason, the scheduled task was not included in the test database.
If one of these situations arose during the execution of tasks by a routine task that are associated only with their database, then this does not have negative consequences. But, often, a routine task can save files or other data, send emails, and conduct exchanges. In this case, confusion may arise between the results of the “job” and the copies. To prevent this from happening, you need to disable “tasks” in the server management console.
Completed and not completed regulatory tasks
When creating routine tasks, it is important to check whether the task can be executed as a routine task. It's important to know that the server module doesn't do many things that are possible on the client. Further, a task that deals with something that is outside the database - an important role in this is played by the rights of the Windows user under which the task is executed.
The last factor is especially important, since if the module is not executed on the server, then the task cannot be completed in principle. To check, you need to run one task and evaluate the result.
Creating a routine task
Let’s create a routine task “Perform processing”.
Let's disable the use of the scheduled task so that when updating the configuration it will not run automatically.
Let's assign a procedure that will be triggered when a routine task is launched:Module of RoutineTasks.RoutineTaskExecutionProcessing.
The procedure itself looks like:
Procedure RoutineTaskExecutionProcessing(Key) Export
Parameters of RoutineTasks.PerformProcessingWithParameters(Key);
EndProcedure
We create a reference book for routine tasks
Our routine task can spawn many background processes - one for each processing. Each task in the 1C8 platform has a key. But the scheduled job method does not know the background job key, so you need to use the background job parameters. As a result, we can see the background job in the job console, but we cannot manually create a background job from this console, because jobs with parameters are not created manually.
Reference book “Parameters of scheduled tasks” :

Requisites :
· CodeBefore Launch- unlimited string - code in 1C language that must be executed before launch.
· Processing from the configuration - line (100) - processing identifier from the configuration
· Processing from the directory - line (100) - link to the directory element “External Processing”, if there is one in the configuration
· Execute through the 1C application - Boolean - a separate 1C application will be created and a routine task will be launched in it. Created for 8.1, where not all application methods are available on the server where the scheduled job is running.
· Launch Code- - unlimited line - code in 1C language that will be executed when a scheduled task is launched.
Let's create the element form :

By clicking on the button “Create reg. task" a routine task with a key code is created programmatically:
Procedure BasicActionsFormCreateReglTask(Button)
Variable Job;
Key = AbbrLP(Code);
Task = RoutineTasks.CreateRoutineTask("PerformProcessing");
Task.Name = Key;
Task.Key = Key;
Parameters = New Array();
Parameters.Add(Key);
Task.Parameters = Parameters;
Task.Write();
EndProcedure
Starting a scheduled task
Each routine task we create has a key:

This key corresponds to the code in the “Parameters of routine tasks” directory; it is used to search when starting a task. If the directory entry is not found, the task is not executed.
Next, if the code is givenCodeBefore Launch then this code will be executed. Next, if the variable Fulfill evaluates to false, the task will not be completed. Variable available for analysis Options, where a link to the found directory element “Parameters of routine tasks” is stored.
Depending on the selected values of the details, either the code in the 1C language will run, or processing from the configuration will start, or processing from the standard “External Processing” reference book will start.
For 1C81, execution is provided in a new application - so that you can use code that is only available on the client, including the use of external processing. To do this, you need to check the “Run through 1C application” checkbox. Otherwise, the scheduled task will be executed on the server.
I recommend setting a user in the “User” field for a newly created routine task, so that the task is executed under certain rights. I recommend giving such a user full rights. I use the user "robot».
The routine task schedule is created using the “Schedule” hyperlink from the routine task form. You can use the “Routine Task Console” processing.
1 Job mechanism
2 Background jobs
3 Scheduled tasks
4 Features of performing background jobs in file and client-server versions
5 Creating metadata for a routine task
6 Job Console
7 Working with routine tasks
7.1 Job objects
7.2 Getting a list of tasks
7.3 Creation
7.4 Uninstallation
7.5 Getting a job object
Job mechanism
The job engine is designed to perform any application or functionality on a schedule or asynchronously.
The task mechanism solves the following problems:
- Ability to define regulatory procedures at the system configuration stage;
- Execution of specified actions according to schedule;
- Making a call to a given procedure or function asynchronously, i.e. without waiting for its completion;
- Tracking the progress of a specific task and obtaining its completion status (a value indicating whether it was successful or not);
- Obtaining a list of current tasks;
- Ability to wait for one or more tasks to complete;
- Job management (possibility of cancellation, blocking of execution, etc.).
The job mechanism consists of the following components:
- Metadata of routine tasks;
- Regular tasks;
- Background jobs;
- Task Scheduler.
Background jobs are designed to perform application tasks asynchronously. Background tasks are implemented using the built-in language.
Scheduled tasks - designed to perform applied tasks on a schedule. Routine tasks are stored in the information base and are created based on metadata defined in the configuration. Metadata of a regulatory task contains information such as name, method, use, etc.
A routine task has a schedule that determines at what times the method associated with the routine task must be executed. The schedule, as a rule, is specified in the information base, but can also be specified at the configuration stage (for example, for predefined routine tasks).
The task scheduler is used to schedule the execution of routine tasks. For each scheduled job, the scheduler periodically checks whether the current date and time matches the schedule of the scheduled job. If it matches, the scheduler assigns that task to execution. To do this, for this scheduled task, the scheduler creates a background task, which performs the actual processing.
Background jobs
Background jobs are convenient to use to perform complex calculations when the result of the calculation can take a long time to obtain. The job engine has the means to perform such calculations asynchronously.
Associated with a background job is a method that is called when the background job runs. A background job method can be any procedure or function of a non-global common module that can be called on the server. Background job parameters can be any values that are allowed to be passed to the server. The parameters of a background job must exactly match the parameters of the procedure or function that it calls. If the background job's method is a function, its return value is ignored.
A background job can have a key - any application value. The key introduces a restriction on the launch of background jobs - only one background job can be executed per unit of time with a specific key value and a given background job method name (the method name consists of the module name and the name of the procedure or function). The key allows you to group background jobs that have the same methods according to a specific application characteristic so that no more than one background job is executed within one group.
Background jobs are created and managed programmatically from any connection. Any user is allowed to create a background job. Moreover, it is executed on behalf of the user who created it. A user with administrative rights or the user who created these background jobs is allowed to receive tasks, as well as wait for their completion, from any connection.
A background job is a purely session object and does not belong to any user session. For each task, a special system session is created, running on behalf of the user who made the call. Background jobs do not have persistent state.
A background job can spawn other background jobs. In the client-server version, this allows you to parallelize complex calculations across cluster worker processes, which can significantly speed up the calculation process as a whole. Parallelization is implemented by spawning several child background jobs and waiting for each of them to complete in the main background job.
Background jobs that complete successfully or fail are stored for 24 hours and then deleted. If the number of completed background jobs exceeds 1000, the oldest background jobs are also deleted.
Scheduled tasks
Scheduled tasks are used when it is necessary to perform certain periodic or one-time actions according to a schedule.
Scheduled tasks are stored in the information base and are created based on the metadata of the routine task defined in the configuration. Metadata specifies such parameters of a routine task as: called method, name, key, possibility of use, sign of predetermination, etc. When creating a routine task, you can additionally specify the schedule (can be specified in the metadata), values of the method parameters, name of the user on whose behalf the carry out routine tasks, etc.
The creation and management of scheduled tasks is performed programmatically from any connection and is permitted only to users with administrative rights.
Note. When working in the file version, it is possible to create and edit routine tasks without launching the task scheduler.
Associated with a routine task is a method that is called when the routine task is executed. The routine task method can be any procedure or function of a non-global common module that can be called on the server. The parameters of a routine task can be any values that are allowed to be transmitted to the server. The parameters of a routine task must exactly match the parameters of the procedure or function that it calls. If the routine task method is a function, then its return value is ignored.
A routine task can have a key - any application value. The key introduces a restriction on the launch of scheduled tasks, because per unit of time, among routine tasks associated with the same metadata object, only one routine task with a specific key value can be executed. The key allows you to group routine tasks associated with the same metadata object according to a specific application characteristic so that no more than one routine task is performed within one group.
During configuration, you can define predefined routine tasks. Predefined routine tasks are no different from regular routine tasks, except that they cannot be explicitly created or deleted. If in the metadata of the scheduled task it is set sign of a predetermined routine task, then when updating the configuration in the infobase, a predefined routine task will be automatically created. If the predetermined flag is cleared, then when updating the configuration in the infobase, the predefined routine task will be automatically deleted. The initial values of the properties of a predefined scheduled task (for example, a schedule) are set in the metadata. In the future, when the application is running, they can be changed. Predefined routine tasks have no parameters.
The routine task schedule determines at what times the routine task should be run. The schedule allows you to set: the date and time of the start and end of the task, the execution period, the days of the week and months by which the scheduled task must be performed, etc. (see the description of the built-in language).
Examples of routine task schedules:
Every hour, just one day
RepeatDays Period = 0, RepeatDays Period = 3600
Every day once a day
RepeatDays Period = 1, RepeatDays Period = 0
One day, one time
PeriodRepeatDays = 0
Every other day once a day
PeriodRepeatDays = 2
Every hour from 01.00 to 07.00 every day
PeriodRepeatDays = 1
Repeat PeriodDuring Day = 3600
Start Time = 01.00
End Time = 07.00
Every Saturday and Sunday at 09.00
PeriodRepeatDays = 1
Days of the Week = 6, 7
Start Time = 09.00
Every day for one week, skip a week
PeriodRepeatDays = 1
PeriodWeeks = 2
At 01.00 once
Start Time = 01.00
Last day of every month at 9:00.
PeriodRepeatDays = 1
DayInMonth = -1
Start Time = 09.00
Fifth day of every month at 9:00
PeriodRepeatDays = 1
DayInMonth = 5
Start Time = 09.00
Second Wednesday of every month at 9:00
PeriodRepeatDays = 1
DayWeekInMonth = 2
Days of the Week = 3
Start Time = 09.00
You can check whether a task is running for a given date (the RequiredExecution method of the ScheduleTasks object). Scheduled tasks are always performed under the name of a specific user. If the user of the scheduled task is not specified, then execution occurs on behalf of the default user who has administrative rights.
Routine tasks are executed using background tasks. When the scheduler determines that a scheduled task should be launched, a background job is automatically created based on this scheduled task, which performs all further processing. If this routine task is already running, it will not be run again, regardless of its schedule.
Scheduled tasks can be restarted. This is especially true when the routine task method must be guaranteed to be executed. A routine task is restarted when it terminates abnormally, or when the worker process (in the client-server version) or the client process (in the file version) on which the routine task was executed is terminated abnormally. In the scheduled task, you can specify how many times it needs to be restarted, as well as the interval between restarts. When implementing the restartable routine task method, you must take into account that when restarted, its execution will start from the beginning, and not continue from the moment of abnormal termination.
It's important to remember that End time will not necessarily complete the background job at the specified time. Some statements:
* A background job can ignore its automatic cancellation if it is not stuck but continues to run for some reason
that not all platform operations can be reversed. If the built-in language cyclic code is executed, then cancel the job
maybe otherwise no. It all depends on what the job does.
* End time - the boundary within which a task can start rather than end?
* Forced termination of a task rolls back the changes made to the start of the transaction?
Features of executing background jobs in file and client-server variants
The mechanisms for executing background jobs in the file and client-server versions are different.
- In the file version, you need to create a dedicated client process that will perform background jobs. To do this, the client process must periodically call the global context function ExecuteJobProcessing. Only one client process per infobase should process background jobs (and, accordingly, call this function). If a client process has not been created to process background jobs, then when programmatically accessing the job engine, the error “Job Manager is not active” will be displayed. It is not recommended to use a client process that processes background jobs for other functions.
Once the client process processing background jobs is started, other client processes are able to programmatically access the background job engine, i.e. can run and manage background jobs.
In the client-server version, a task scheduler is used to execute background jobs, which is physically located in the cluster manager. For all queued background jobs, the scheduler gets the least loaded worker process and uses it to run the corresponding background job. The worker process executes the job and notifies the scheduler of the execution results.
In the client-server version, it is possible to block the execution of routine tasks. The execution of routine tasks is blocked in the following cases:
- An explicit blocking of routine tasks has been installed on the information base. The lock can be set via the cluster console;
- There is a connection block on the infobase. The lock can be set via the cluster console;
- The SetExclusiveMode() method with the True parameter was called from the built-in language;
- In some other cases (for example, when updating the database configuration).
Creating metadata for a routine task
Before you programmatically create a routine task in the infobase, you need to create a metadata object for it.
To create a metadata object for a routine task in the configuration tree in the “General” branch for the “Routine tasks” branch, execute the “Add” command and fill in the following properties of the routine task in the properties palette:
Method name - indicate the name of the routine task method.
Key - specify an arbitrary string value that will be used as the key of the scheduled task.
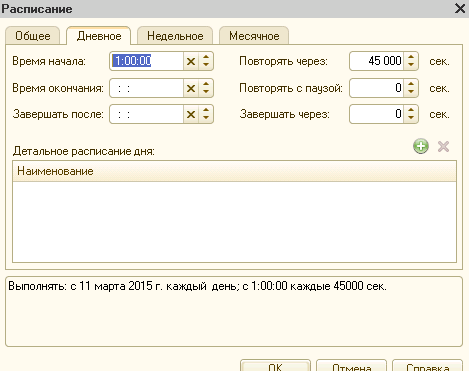
Schedule - indicates the schedule of the routine task. To create a schedule, click the “Open” link and in the schedule form that opens, set the required values.
On the “General” tab, the start and end dates of the task and the repeat mode are indicated.
On the “Daily” tab, the daily schedule of the task is indicated.
Please indicate your schedule:
- start time and end time of the task;
- the task completion time, after which it will be forced to terminate;
- task repetition period;
- duration of pause between repetitions;
- execution duration.
It is allowed to specify an arbitrary combination of conditions.
On the “Weekly” tab, the weekly schedule of the task is indicated.
Select the checkboxes for the days of the week on which the task will be executed. If you want to repeat the task, specify the repeat interval in weeks. For example, the task is executed in 2 weeks, the repeat value is 2.
On the “Monthly” tab, the monthly schedule of the task is indicated.
Select the checkboxes for the months in which the task will be executed. If necessary, you can specify a specific day (month or week) of execution from the beginning of the month/week or the end.
Usage - if set, the task will be executed according to the schedule.
Predefined - if set, the task is a predefined task.
Number of retries in case of abnormal termination - indicates the number of retries in case of abnormal termination.
Retry interval on abnormal termination - specifies the retry interval upon abnormal termination. Examples
Creating a background job “Full-text search index update”:
BackgroundTasks.Run("UpdatingFullTextSearchIndex");
Creating a routine task “Recovery of sequences”:
Schedule = New ScheduleTask;
Schedule.PeriodRepeatDays = 1;
Schedule.RepeatPeriodDuringDay = 0;
Task = RoutineTasks.CreateRoutineTask("Restoring Sequences");
Job.Schedule = Schedule;
Task.Write();
Job Console
Processing with ITS, manages routine tasks: ConsoleTasks.epf
Working with routine tasks
Job Objects
Job objects are not referenced, but are stored in the database in some special storage.
If the "Predefined" flag is enabled in the metadata, then such an object is created automatically when 1C:Enterprise is launched and always exists in exactly one instance. Such an object cannot be deleted.
If the "Predefined" flag is not set, then objects of such a task are created and deleted programmatically, specifying the schedule and parameters.
Getting a list of tasks
The list of tasks can be obtained using the method Get RoutineTasks global job manager RoutineTasks
ScheduledJobsManager
Get ScheduledJobs (GetScheduledJobs)
Syntax:
Get RoutineTasks(<Отбор>)
Options:
<Отбор>(optional)
Type: Structure. Structure defining selection. Structure values can be: UniqueIdentifier, Key, Metadata, Predefined, Usage, Name. If selection is not specified, all routine tasks are obtained.
If you are filtering by metadata, then as the Metadata value you can specify either the metadata object of the routine task or its name.
Return value:
Type: Array.
Description:
Receives an array of routine tasks for a given selection. Receiving scheduled tasks is only possible for the administrator.
Availability:
For Each Regular of the Regulatory Cycle
NewLine = List of ScheduledTasks.Add();
NewRow.Metadata = Regular.Metadata.View();
NewLine.Name = Regular.Name;
NewString.Key = Regular.Key;
NewLine.Schedule = Schedule.Schedule;
NewLine.User = Regular.UserName;
NewString.Predefined = Regular.Predefined;
NewString.Use = Regular.Use;
NewString.Identifier = Regular.UniqueIdentifier;
LastTask = Regular.LastTask;
If LastTask is Undefined Then
NewLine.Running = LastTask.Start;
NewRow.State = LastTask.State;
endIf;
EndCycle;
Creation
Created by the Create RoutineTask method for the manager of routine tasks:
RoutineTask = RoutineTasks.CreateRoutineTask(MetadataSelection);
RegularTask.Name = Name;
RegularTask.Key = Key;
RegularTask.Use = Usage;
RoutineTask.UserName = UsersSelection;
RoutineTask.Number ofRepetitionsAtEmergencyCompletion =NumberofRepetitionsAtEmergencyCompletion;
ScheduledTask.RepeatIntervalAtEmergencyCompletion = RetryIntervalAtEmergencyCompletion;
ScheduleTask.Schedule = Schedule;
RegularTask.Record();
TaskObject = RoutineTasks.CreateRoutineTask("ExchangeExchange");
TaskObject.Name = Name;
JobObject.Use = True;
The task object has a "Parameters" field in which the method parameters are specified:
ScheduledJob
Parameters
Usage:
Read and write.
Description:
Type: Array. An array of parameters for a scheduled task. The number and composition of parameters must correspond to the parameters of the routine task method.
Availability:
Server, thick client, external connection.
Note:
Read and write capabilities are available only to the administrator.
Removal
Deleted using the Delete() method of the task object:
ScheduledTask.Delete();
Getting a Job Object
- list via the GetRoutineTasks method:
Routine = RoutineTasks.GetRoutineTasks(Selection); - via the FindByUniqueIdentifier of the task manager method:
Task = ScheduledTasks.FindByUniqueIdentifier(UID);
[you must register to view the link]
Probably, not a single serious configuration on 1C 8.3 or 8.2 can do without the use of routine and background tasks. They are very convenient, since they will be executed according to a clearly defined schedule without user or programmer intervention.
For example, you need to exchange data with another program once a day. Using routine and background tasks, 1C will be able to perform these actions independently, for example, during non-working hours. This method will not affect the user experience in any way and will help save time.
First, let's figure out what they mean and what is their difference:
- Scheduled task allows you to launch any specific actions according to a pre-configured schedule.
- Background job is an object that contains the actions to be performed.
Let's assume that our company sells something and has its own website where prices are located. We want to upload them once a day to maintain relevance.
Open the configuration and add a scheduled task.
Setting properties
Let's look at the most important parameters that need to be filled in its properties.

- In field " Method name» selects the procedure of a specific general module that will be directly executed. It will indicate all the steps for uploading prices to our website. Please note that execution will take place on the server. This is logical, because routine operations are performed without user participation.
- The scheduled task can be disabled or enabled as needed. There is no need to edit his schedule every time. To do this, in the properties palette, set or clear the flag " Usage».
- Another important thing is to set whether this routine task will be predetermined, or not. Predefined routine tasks are launched automatically. If this flag is not installed, then you will need to launch them programmatically, or use the “Task Console” processing with ITS.
- You can also specify number of repetitions and interval between them in case of abnormal termination. Abnormal completion refers to those situations when jobs were not completed due to an error.
Setting up a schedule
The final step is to set up a schedule for our upload to the site using the corresponding hyperlink in the properties palette.

You will see a typical schedule setting in 1C 8.3. There is nothing complicated here. In this example, we configured the launch of our uploading of prices to the site daily from five to seven in the morning. In the event that the scheduled task does not have time to be completed before 7:00, it will be completed the very next day.

Blocking scheduled tasks
Run the standard utility “Administering 1C Enterprise Servers” and open the properties of the infobase where you created the routine task (for client-server versions of 1C).

In the window that opens (after entering your login and password to access the information security), check that the checkbox “Blocking of routine tasks is enabled” is not selected. If you encounter a situation where the task does not work, check this setting first.

In the same way, you can completely disable routine tasks in 1C 8.3. To disable specific background jobs, you can use the “Background Job Console” processing built into the latest releases.
Background and scheduled tasks in file mode
In this mode, setting up and launching these tasks is much more difficult to organize. Most often, an additional account is created, the session of which will always be open.
In this case, routine tasks are activated using the “RunTaskProcessing()” method.
You can also use the following construction:
As the procedure name, you must specify the name of the client procedure that will be executed. The interval shows how many seconds later the execution will take place. The “One time” parameter is not required. It reflects whether this procedure will be performed once or several times.
Tracking errors in background jobs
You can view the progress of background jobs, as well as the presence of possible errors, in the log. In the filter, set the selection to the “Background job” application and, if necessary, select the importance of interest, for example, only “Errors”.

The log will show all entries that match your selection, along with a comment that will help you understand the reason for the error.


